作为互联网的土著企业滴滴快的打车快速抢单加速器,快的和京东都分得滴滴快的打车快速抢单加速器了互联网大数据的第一杯羹。下一轮滴滴快的打车快速抢单加速器,他们图谋更广阔的产业生态圈。
快的打车“超级大脑”数据变现记
“分秒”之间的多轮筛选,数据完成的用户画像系统,人们点滴的打车轨迹正在汇聚成就一个全新的商业生态。
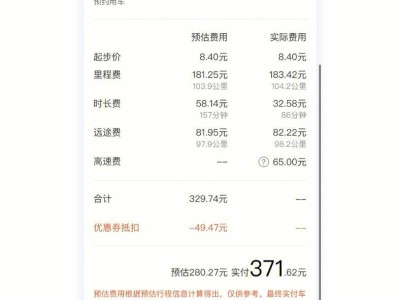
周五晚上6点40分,李菲(化名)在离家不到3公里的地方,用打车软件叫滴滴快的打车快速抢单加速器了一辆出租车,在不到1分钟的时间、系统通知了附近43辆出租车之后显示被抢单,与此同时,李菲的手机上收到一条短信:“我们额外支付了司机11元,这部分费用由土豪快的买单。”
这次打车给李菲带来的愉悦感可想而知:之前望眼欲穿的苦等,现在则分秒可得。不过李菲或许不知道的是,从她按下快的界面的叫车键到系统启动用车通知“分秒”之间,快的后台已经完成了多轮筛选:根据用户画像和用车需求,匹配位置合适的出租车,再结合实时的地理位置和运能状况确立给后者的补贴金额——这些计算都是在毫秒内实现。甚至在更早之前,快的已经根据她的历史打车的行为特点,将其划归到了“屌丝”的标签之下,由此她才频繁收到金额不小的代金券。
2012年开始成立的快的迅速地网络了360个城市中上亿员“快乐的大多数”:每天,300多万订单生成,每个小时,数十万订单数据汇入快的后台。而李菲们所不知道的是,他们的点滴打车轨迹正在汇聚成就一个全新的商业生态,而这也正是快的等打车软件的未来疆场。
用户画像:屌丝和土豪的不同行为轨迹
快的“土豪式”补贴背后,其实也有着它自己的精打细算。就如快的公司技术副总裁朱磊对记者所说的,行业已经从粗暴的跑马圈地走入了精耕细作的时代,要花更少的钱获取更多的用户。
精准营销的前提是对用户的清晰认知。以简单的代金券发放为例,快的的历史数据呈现出两大类四种不同的消费习惯—代金券敏感型:发代金券才用、发代金券用的更多;代金券不敏感型:发不发都用,发代金券也不用。在快的的用户画像系统中,上述四种群体会被分别冠以屌丝、普通、中产、土豪的标签。针对四类客群的运营策略也会全然不同,最直接的就是代金券的刺激频率以及刺激金额,而对“代金券”免疫的土豪群体,则更多地需要在服务上做文章。
而在实际场景中,影响乘客对应用软件的使用黏度的因素要远比代金券复杂得多,在这种情况下,快的对用户的“贴身跟踪”就能及时发现薄弱环节,因此从用户打开软件到退出使用,其间的每一步情况都被快的记录在案:哪一天退出的,哪一步退出的,退出之后“跳转”到什么软件等等。
据此,快的也实现了用户另外一个纬度的归类,分清哪部分是忠实用户,哪部分可能是潜在的忠实用户,哪些则是已经流失的;更进一步来看流失的原因:因为代金券没有了流失滴滴快的打车快速抢单加速器?软件体验不好流失?还是等车时间太长而流失?—这些都是下一步精准营销的依据。
而对于快的而言,用户分析不仅仅是针对乘客,也包括司机、出租车公司的所有相关方。尽管基础信息大同小异,都包括人的基本信息、信用、行为信息等;也有一些通用的刺激手法,比如积分、礼物等。不过,不同的用户画像就对应了不同的刺激程度,而结合不同的场景,还是许多特殊的营销安排。

杭州市场就是一个很典型的例子。基于司机的地理位置信息,快的发现每天中午或者是每天晚上10点以后,司机都会聚集在一些固定的地点,可能休息或者就餐。所以快的就会在这些场所提供一些工作餐或者是优惠食品,通过线下的活动来提升司机和快的的合作关系。
产品生成的逻辑:更精确地匹配供需
维护好用户只是一个基础,最终目的是为了打通供需,生成更加优化的服务和产品。这也正是数据之于打车软件此类的O2O行业的重要性所在。“数据能解决一个核心问题,就是做供需双方的智能匹配。”朱磊说。
其实也很容易理解,公交、出租车、地铁都是对出行人群不同需求的对号入座,不过这样被朱磊称之为“粗暴式”的分类法应用起来效率低下,以一个司空见惯的打车场景为例,在路边拦车,可能许久都没有空车经过,或者是好不容易等到的车,司机问了地址之后还可能拒载—呈现一种杂乱无章的状态。
而在海量的数据基础之下,出行的需求被不断细分,而且是实时匹配。例如一个乘客下单之后,需求方的用户图像和需求同时被识别,结合供方的车辆条件和位置地图进行第一轮筛选,不过这个看似“正常”的订单却不一定符合实际,因为有一些订单发出来是司机不愿意接的,比如高峰时段的拥挤路段,那么在这个时候就要进行订单评估和内部调节,结合历史数据制定一些刺激措施、叠加“乘客自行出的小费”来诱导司机,这样一个符合供需双方胃口的“合理”订单就生成了,下一步要做的就是实时调度,要考虑当时的交通情况、车的朝向、车速、附近是否有突发性事件等等因素,选择最为优化的方案。
完成了以上的步骤之后,快的才会把用车需求和奖励方案推送给经过层层筛选之后的出租车,这样李菲们打车的成功率大大提升了,而且所用的时间更短。“这是以前所有的产品做不到的,因为不能洞悉消费者的心理。在大数据应用下,消费者和供给方能够省略中间环节直接议价,这是一个模式上的变革性的突破。”而最终海量的议价数据将提炼成为一种“商业情报”,来推动新的产品和新服务的推出,比如智能定价系统,以从机场到望京这一段司机不愿意接的单为例,可能70%的乘客额外加了20块钱,少数人加了30块钱,而有的只愿意加10块钱,那么系统整合分析以后会得出21元钱是一个更合适的议价,那么最终的定价可能消费者和司机双方都可以接受。
因此,以这样的逻辑推导生成的产品才更能有的放矢,因为其生成不是来自于企业对市场的臆断,而是直接提炼于供需双方的心理预期和真实需求。
“回程单”的产品创设就是一个很典型的例子。最初是快的的数据分析发现一个异常的数据现象,就是司机的抢单意愿率在某一个时点会骤然下滑,过一段时间又会反弹,日日如此。通过对这个特殊节点分析,快的得出一个司机运营的特殊场景,就是司机收工的时间,接下来就是针对性地解决,因为不管司机是交班还是回家,肯定有一个固定的方向—这一点可以通过历史数据分析出来。那么快的要做的就是把同样去往这个方向的乘客分配给对应的司机;这样做是否就一定见效?所以下一步就要评估效果,看回程单是否真正提高了司机的抢单意愿,确定之后才能作为常规产品推出。
“产品的细分应用场景将会越来越依赖于大数据分析,从数据中洞察需求与商机,再结合大数据提供应用解决方案,将变成未来产品迭代的常规运作模式之一。”朱磊说,这也是快的产品的生成逻辑。
由“女神去哪儿”所引发的盈利模式畅想
不过正如朱磊所说,打车软件可以让传统的商业模式更加高效,更加酷,那么它的盈利模式又是什么?
当然,可以简单地收取一种平台佣金:司机做成一单交易,打车软件从中进行提成。且不说现在很少有司机愿意支付这种新兴的“份子钱”,而且这样一种缺少差异性的盈利模式需要寄生于垄断的生态条件下,而打车软件市场显然不符合这个条件。
机会正隐藏在数据密码中。2014年,快的打车发布了名为“七夕,女神都去哪儿了”的全国各地女生用车报告。数据显示,8月2日七夕节当日女生叫车时间最高峰为22点10分,其中叫车目的地为饭店占比最高的前五名分别为广州(49%)、重庆(40%)、上海(38%)、北京(35%)和深圳(34%),叫车目的地为酒店的占比前五名则分别是,长沙(53%)、深圳(49%)、杭州(46%)、上海(45%)、北京(43%)。
对于快的来说,这不是娱乐八卦噱头,这里至少暗含了两大“宝藏”,一个是知道特定时间的特定人群的聚集地,另一个则是特定人群在某段时间的消费行为。
快的在接下来的4、5月份将要上线的需求预测系统和运能预测系统就是基于对上述第一点的掌握,司机借此可以看到整个北京城的实时用车需求:什么位置需求旺盛,同时运能严重不足。这样也就避免了司机“听天由命”的状态:在马路上毫无目的地空转。
而掌握了某一群体特定时间的消费行为这件事则具有更大的想象空间,基于乘客目的地周边的商铺而提供的广告服务,也是快的未来业务一个最重要的落脚点。在朱磊看来这也将颠覆传统的互联网广告模式,“传统的广告,消费者是比较被动的接受者,最终形成真实的购买行为的转化率很低,而打车软件承载的是人、时间、空间多维度结合的生活场景,个性化推荐更加投其所好,贴近实际,转化率会高得多。”这个判断也来自于快的大量的数据分析,用户研究显示了其中30%有非常明确的商业需求,50%是潜在的消费群,那么快的就可以在用户出行途中来推送目的地的商铺优惠信息。
这只是一个粗略的模式雏形,如果有更细致的用户行为分析就可以使广告推送更加的精准。比如快的对用户行为跳转的研究发现,用户在叫车结束退出APP之后,很多会打开团购网站搜索电影票、餐饮券等等,那么如果一个用户想打车去星美国际影城,那么快的和团购网站合作推出的团购票说不定就会正中用户的心思。
在朱磊看来,这类结合出行过程和目的地分析的广告模式将会焕发更大的生命力,同时也广泛适用于其他的出行情境,包括出租车、专车、地铁、公交一系列的出行方式在内。“只和人和目的地相关,可以在大的出行生态里面做成相对通用的广告系统,后续可以和更多其他的APP合作。”据朱磊透露,这一套让“数据变现”的系统将在4月底的时候投入运行。
跨界的数据“火花”
尽管快的野心不小,想要构建一个全新的广告“生态”,不过这显然不是快的凭借一己之力所能实现的,必须借助于外部数据的导入——这恐怕也是大数据应用最基本的要求,那就是开放和共享。
与阿里和美团等的合作就实现了双方数据的相互补充,“他们缺乏出行数据,我们目前缺失的是用户的消费数据和信用数据。”朱磊说。在此基础上就可以共建用户画像体系:工作地点、家庭地点、消费情况、价格敏感度等等。
在一个完整的用户图像下,广告推送就会更加的精准。比如定位到一个北京用户打车去西单,在分析出其消费偏好的基础上,就可以针对性地发送特定商场特定店铺的某一类产品的优惠信息。“量身定做的实时实地的广告价值将远远超过传统广告盲目推送的方式。”一些针对节日的广告类型也会应运而生。以七夕节为例,就可以首先圈定跟节日消费相关的群体,提前两天推送花店信息,可以在节日当天直接送花上门,甚至可以制造一些小“浪漫”:或许可以设想一下当你的女朋友看到一辆豪车来接她下班时的惊喜,而车上还放着她喜欢的音乐,外加一束娇艳的玫瑰花。
完美的畅想还不得不面对现实中固有的一些问题,就像朱磊说的,一个来自于不同的行业标准和数据标准所带来的数据通用的难题,而即便在技术共享上不存在障碍,而协商机制的建立也将是一个漫长的“对话”。
“数据的价值评判每一家都是不一样的,那么就需要跨界的共赢机制的建立,这个在历史经验上是不存在的,只能去摸索磨合,这个过程肯定是痛苦的。”朱磊说。
数据驱动模式的基础:技术投入
尽管还存在不少待解难题,如今开始把关注焦点转向数据驱动模式的快的,都已经与“补贴大战”时不可同日而语。因为任何的新兴业务,不论发展初期如何势如破竹,也必然要经过一个商业模式的探索和沉淀,否则最终会被“价格战”拖得精疲力竭。
“经过初期的野蛮生长之后,还想获得跨越式发展,就肯定需要在技术上的重点投入。”曾担任百度云计算主要负责人的朱磊,在快的带领的团队主要负责大数据体系、商业体系、基础架构与新业务等方向。
这个三四十人的团队在最初的三个月,经过了朱磊所说的“苦活、脏活、累活的痛苦历程”,进行了数据导入、清洗、存储、结构化等一系列最基础的处理,最终建成了快的的大数据体系。据朱磊介绍,目前扩建后团队的核心力量正在进行大数据2.0系统的研发。这套内部代号为“地平线系统”的大数据架构,克服了1.0系统中突出的数据数量与数据质量、处理速度之间的矛盾,实现了数据纯度、处理速度的跨越式升级。
这个“超级大脑”支撑了快的大数据应用所需要的所有基础数据,在此之上是支持产品、商业、运营商业化的团队,每个配备了20个人左右。这样的架构实际上避免了基础数据和应用数据之间的“污染”问题,比如一个需求场景形成了A的画像集合,其中结合B行业又会出现一个AB子集,应用到特殊的场景C之后又会形成一个同时满足ABC的集合。如果每次都从基础数据抽取的话,就很容易影响基础数据的稳定性。
清晰的数据架构对于“每秒(毫秒)都产生海量数据”的快的来说,重要性不言而喻。而今,数百台的机器支撑着的快的大数据系统在朱磊看来,就像是公司的“心脏”:业务规模越大,越是重要。
这种投入不是任何一个公司都能够负担的,却是每一个公司都应该及早想清楚的,“过早投入的话,对精力和资本消耗太大,不过如果之前缺乏考虑,后面就要做很多工作才能把之前错失的那些数据漏洞补回来。”对于早期一直争抢用户市场、而忽略了数据应用的快的来说,这恐怕也是宝贵的“经验之谈”了。








1 留言